AI Pet - Dev Blog 2
Pet Simulator demo (click to play, with commentary)
While all my friends are using AI to build products to solve real problems, I've decided to the best use of AI is to digitise my pet bunnies (Billy and Millie).
Announcing Pet Simulator a multiplayer 3D browser game built on Babylon.js and Colyseus.
By running this on my kubernetes cluster I can justify my spending habits to my wife as it's now saving me hosting costs. It picks up where part 1 left off, taking a single-player prototype, and turns it into a shared experience powered by an AI brain.
Features:
- A live 3D scene where multiple players can join and interact with the same bunny simultaneously
- An AI bunny whose behaviour is driven by an LLM hosted on my own hardware
- Improved visuals with better sprites and animations
- A custom-trained model that can be hot-swapped into production without downtime
- Full self-hosting — game server, inference worker, and database all run on the Raspberry Pi cluster
New Hardware

My bunnies now live in the corner of my office which I feel better about than them living in some AWS data center! I've updated the hardware slightly, with plans to add more later. I've wired up the network as previously it ran wirelessly, that was putting a lot of pressure on our router. So now I don't get yelled at when we can't connect to our wifi.
I've also added a 16GB Raspberry Pi node (on the left) giving me 5 total nodes. the new node is just to run inference, it gives respectable performance running tiny models on CPU. I also had to upgrade the power supply as my cute minimal setup couldn't provide enough amps to keep the cluster stable under load!
I also know when someone is visiting by bunnies I can hear the raspberry pi CPU cooling activate on my LLM box. 😁 🪭🪭🪭
Challenge: Hardware voltage issues — Now we're stressing the hardware, my previous power supply couldn't deliver enough amps across the cluster causing the master node to become unstable. Raspbery Pis will throttle the CPU if they are underpowered and combined with the volume of Prometheus metrics data flowing through the master node, it couldn't keep up. The cluster periodically became unresponsive and I had to restart it. Better power and moving the monitoring stack off the master and onto worker nodes solved the instability, but diagnosing it took a while since the symptoms looked like OOM (out of memory) errors and software bugs.
Challenge: Resource contention The game server and LLM inference compete for the same CPU and memory on the cluster if not managed, causing nodes to crash. I added labels to nodes with deployment rules so inference STRONGLY prefers the 16GB node and other services avoid using it, also moving monitoring off the master node to avoid overloading it with requests.
High Level Design
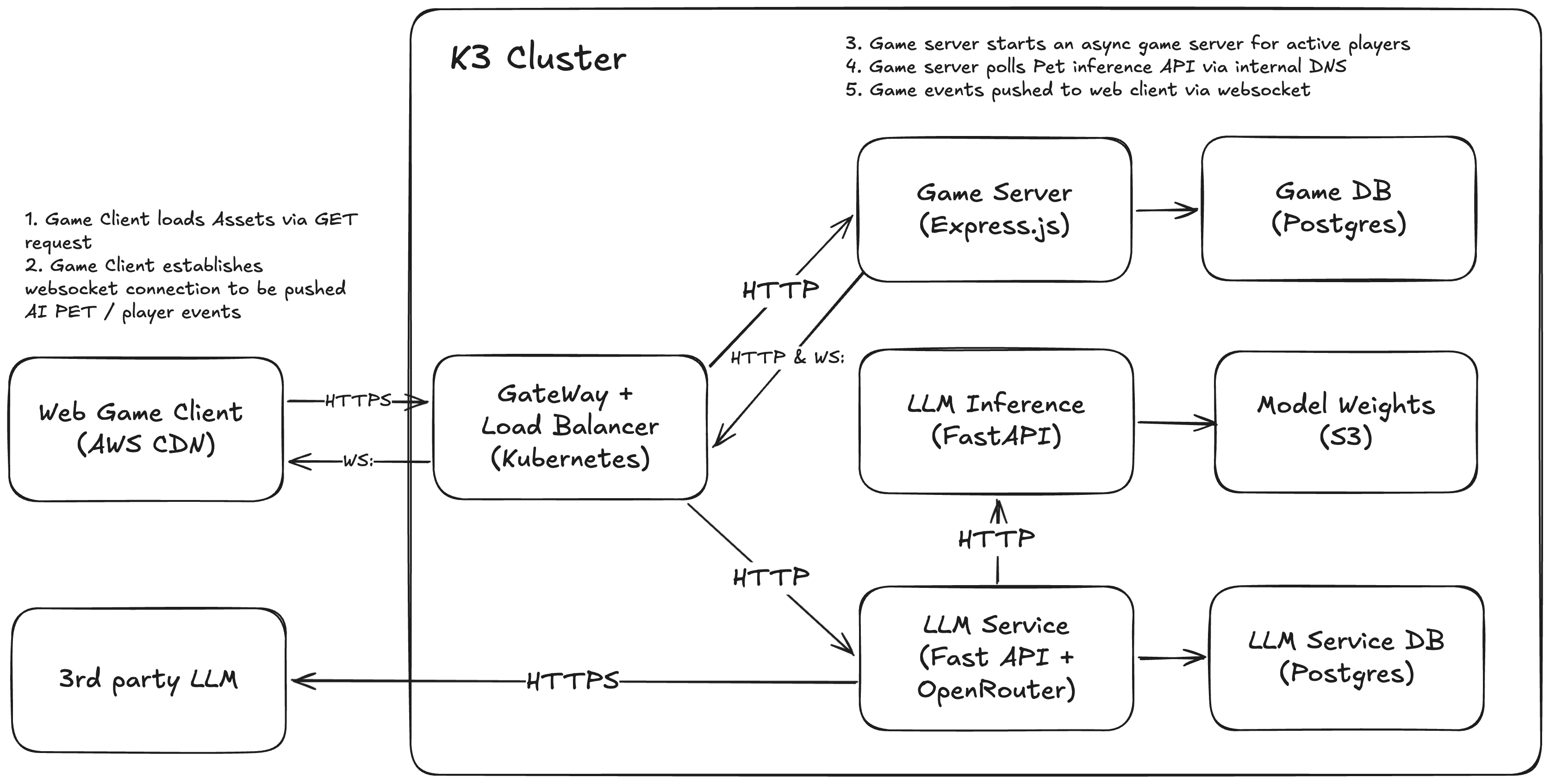
The v1 of aipet was just a single web server and database making API requests to Google Gemini. Supporting multiplayer and self-hosted inference meant adding several more components.
- A multiplayer game server that is low latency
- The game state is stored on the server and shared with all clients
- The game server can access an LLM and use the output to drive the bunny's behaviour
- The LLM container can load different weight files and be changed dynamically without downtime
The backend splits across two languages, each chosen for its strengths: I have to use TypeScript on the brower so it also makes sense for the game server. A friend(?) made me sad by talking me into re-writing the server in typescript. He was right though as the game server can share interfaces and code between the client and server, greatly simplifying game development.
As the LLM proxy and inference services are decoupled, I can use Python and all the LLM libraries / API frameworks I like to use for those.
The data flow looks like this:
- Player connects to web browser client and it establishes a websocket connection with the gameserver
- The game server will start a new game session if one doesn't exist or will add the player to an existing one with other people
- The game loop runs for each game session, recieving player input and sending updates to all connected clients
- The game loop periodically sends a request to the LLM service with scene info including player locations
- The LLM service returns the bunny's next move / dialogue, which the game server incorporates into the scene updates sent to clients
This architecture allows for a responsive multiplayer experience while keeping the AI logic modular and scalable.
The Game Engine
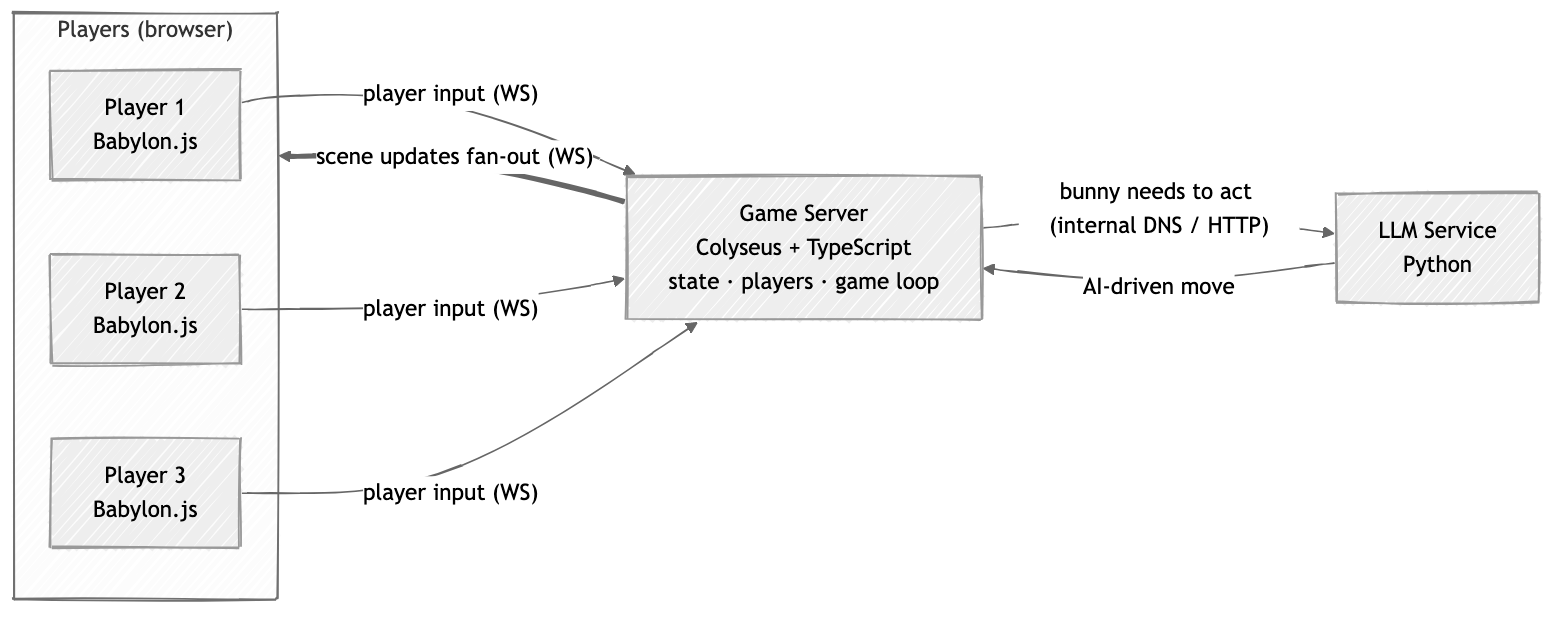
I wanted a solid base with good design patterns for the AI to enhance rather than risk it creating a mess, especially as multiplayer is a hard problem with lots of edge cases. I started from the T5C template, which pairs Babylon.js and Colyseus. Babylon.js is a powerful 3D game engine that runs in the browser, and Colyseus is a multiplayer framework that handles real-time communication and state synchronization between clients and the server.
Colyseus runs the authoritative game state: each WebSocket connection streams player input in, and the server fans the resulting scene updates — including the bunny's AI-driven moves — back out to every connected client.
- Game client — a static React/Babylon.js bundle served from AWS S3 + CloudFront
- Game server — a persistent TypeScript WebSocket server running on my Raspberry Pi cluster, managing scene state and player connections
The LLM Proxy and Inference
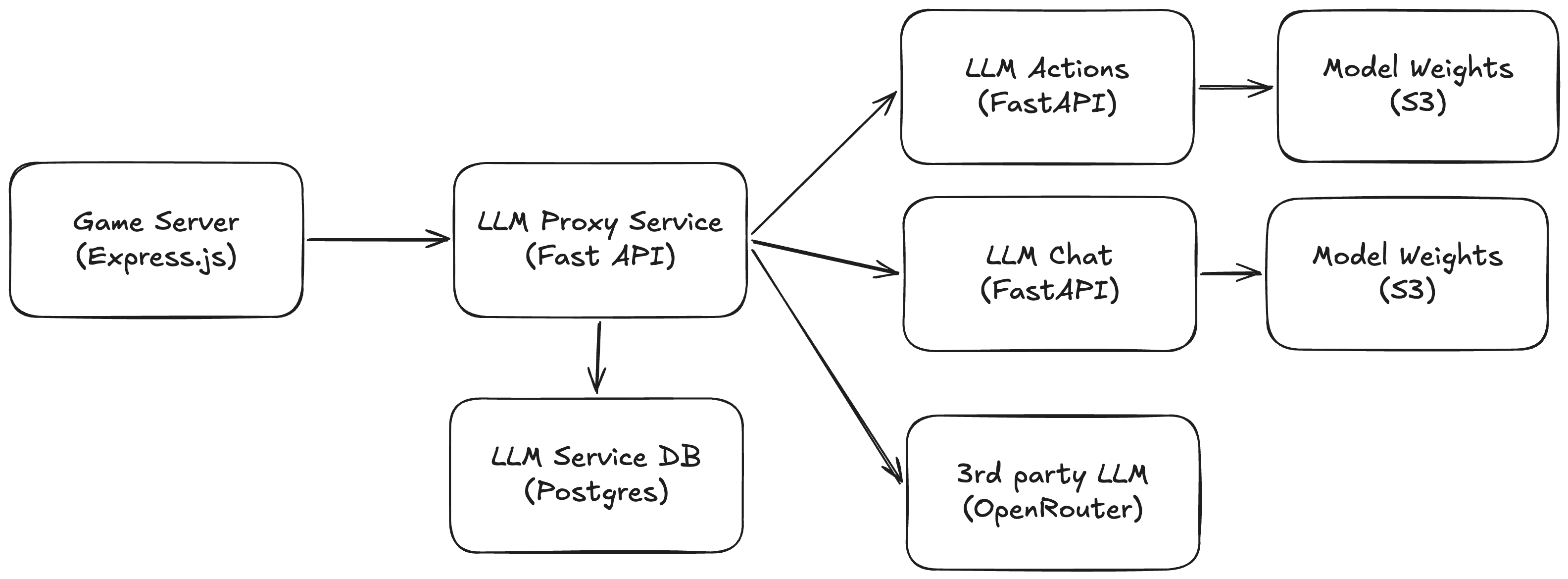
Note: the LLM training is handled separately and will be covered in a follow-up post
The LLM management is split into two components:
- Proxy API — a lightweight Python FastAPI service handling auth, routing, llm settings in a database. No ML dependencies, so it runs cheaply alongside the game server
- LLM Container — Separate, heavier Docker container spun up on demand, running llama-cpp-python. Runs as a Kubernetes pod, shut down when idle, on startup loads weights from a GGUF file stored in S3
Splitting the proxy and inference into separate containers keeps the proxy API performant and makes memory / CPU management in the cluster easier. The inference node has 16GB of RAM, so it can fit two LLM pods. This lets me load a new inference model for the game, handle routing seamlessly, and shut down the old inference pod.
The model is currently HuggingFaceTB/SmolLM2-360M, which is optimised for speed; I can get full responses from inference in 2-3 seconds. I also tried HuggingFaceTB/SmolLM2-1.7B, but inference time rose to 10-15 seconds. After running simple evals the tiny model was returning reasonable answers 95% of the time, which is good enough for now. I'm looking at adding a GPU node then I can use this pattern to load a better model for more complex behaviour and dialogue while keeping response times low.
Now my training service is up, I can easily try more models, which I'll cover in a follow-up post.
Challenge: Hot-swap model loading — Only two inference pods can fit on the 16GB node in memory at a time. Promoting a new model means spinning up a new pod and shutting down the old one to free the RAM. If the release fails or the new model doesn't load cleanly, the game will not be affected and the failing pod will be terminated. I also added a cleanup job that runs periodically to catch any unused inference pods that didn't shut down correctly and could be taking up resources.
End Result & Next Steps

I'm happy with my AI pet project, it has lots of room to grow and I now have a solid framework in place to allow that! Here's the link to Pet Simulator if you'd like to try it out. :) My next steps are; adding more bunnies, re-creating my old pets, adding personalities, adding more actions and seeing where that goes! Let me know what you think would be good features to add.
Here's the github project if you'd like to see the code: github.com/jwnwilson/aipet
Related Posts
- AI Pet Part 1 — building an ai pet prototype with Google Gemini
- Building a LLM Training Pipeline — remote training across Kaggle, RunPod, VastAI, and Kubernetes with Temporal
- Building a Complete Project Using AI as a Solo Dev — how to ship fast without sacrificing quality